Assumption Mapping
Key Insights:
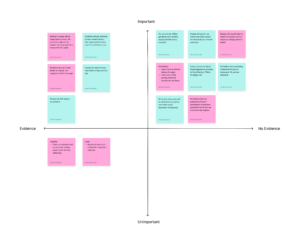
The assumption mapping exercise helped us identify that our most critical and unvalidated assumptions were the ones around user motivation and willingness to take accountability. More specifically, the map showed us that the biggest risks for Unrot lean on the behavioral side rather than the technical side, meaning our success depends less on whether we can build the extension and more on whether users engage with it honestly and consistently.
One of the assumptions was that users would want to actively reduce their AI usage and would accept having boundaries imposed on them by our intervention. These assumptions sit in the high importance, no evidence quadrant, which makes them central to our intervention’s success but still untested. This matters because Unrot’s value is not just showing usage, it is nudging users towards more intention, goal aligned behavior that requires users to be open to reflection and constraint.
The map also surfaces another high importance, no evidence of risk around incentives: people may reward hack the system and improve their Unrot score without actually changing their behavior. If that happens, our ‘progress’ signals become misleading for users and the system, so strong metric design and checks become essential.
Finally, the exercise highlighted that privacy and data access constraints introduce friction, which could drive drop off and reduce retention. Overall, the map helped us to prioritize some key insights on what to test first: willingness to change and accept accountability, whether users game the system, before building the product itself.
Assumption tests:
- AI Use Game Feedback
- We believe that gamifying intentional AI use will make poor AI use less desirable.
- To verify that, we will monitor one AI use session in person and provide visual/verbal feedback in a game format.
- We will measure participants’ motivation to use AI less, before and after, and the participants’ enjoyment of the AI game session
- We are right if participants are more motivated to use AI less and they enjoy the game session
Proposed Game:
-
- Moderator watches user and evaluates their prompts in real time – they are given 10 chocolates to begin with
- If user inputs good prompt, moderator cheers them on with chocolate
- If user inputs bad prompt, moderator takes away a chocolate
- Brain Avatar Preference
- We believe that users will be attached to an avatar over other visual depictions of progress.
- To verify that, we will show participants various visual depictions of progress – such as progress bar, percentage, brain, etc. and see which ones participants resonate with the most. “Assume you are using an app that tracks your progress. Which visual indicator do you prefer? Rate each one on a scale of 1-10.”
- We will measure participants’ ranking of the various avatars out of 5 and evaluate the answers to the qualitative question.
- We are right if the brain avatar ranks highly among users.
- Avatar Surveillance Effect
- We believe that having an avatar will make people feel surveilled/judged so they will act more ethically.
- To verify that, we will ask participants to use AI while a brain avatar lives on the corner of their screen. We tell them that it tracks your AI usage (but the app doesn’t actually.)
- We will measure qualitative factors such as their body language, etc. to gauge how self-aware they feel and we will secure transcripts of their previous AI usage to evaluate their use against that.
- We are right if >50% of test participants use AI differently.