Overview
Basic Study Design
The study was a five-day simulation where participants logged social plans via screenshot and plan artifact submission and received feedback designed to reduce “flakiness”. The intervention utilized a “bot,” which was simulated by the research team and provided risk labels and flake scores (0–100) based on plan specificity and historical reliability.
We recruited 6 participants for this study, 2 of whom were returners from our baseline study, and 4 of whom were new. Each day, participants would send screenshots from text message conversations that were related to the planning or execution of a social plan. For the first two days we merely collected the screenshots. From the third day onwards, we had enough data to start calculating scores, and would send score updates at the end of each day. Scores were calculated based on the quality of planning communication and the degree to which participants followed through on their commitments. Good social hygiene increased the score, and flakiness decreased it.
We originally planned to provide scheduling suggestions in addition to our flake scores, but we realized that the data that we received did not match this need. Specifically, participants tended to send, or remembered to send, screenshots only once a plan was fully formulated. In this case, scheduling assistance was not beneficial because participants had already done the work of scheduling in order to produce screenshots to send to us. This led to one of our major insights and design changes, which is that artifact submission affects the behavior we are measuring, and that our solution must be embedded rather than exernal.
Key Insights from the Study
- Meta-Awareness as a Catalyst for Change: Simply having to report plans made participants more conscious of their behavior. For example, one participant realized how often they actually reschedule, and another was surprised to find that they was making more plans than she previously thought.
- The Power of Low-Risk Labels: Interestingly, being told a plan was “low risk” motivated follow-through. One participant noted that flaking on a low-risk plan felt worse because the bot’s interpretation “normalized” the expectation that they should not flake.
- Friction in Data Collection: The requirement to manually send screenshots was a significant barrier. Several participants “slacked” or sent them all at once at the end of the day, which defeated the purpose of real-time intervention.
- Variable Response to the Score: The flake score had mixed emotional impacts. Some found it validating or fun, while others viewed it as an attempt to shame them.
- Tone and Clarity Issues: Participants found AI-generated suggestions to be too verbose, “unserious,” or impersonal. One participant specifically noted that the suggestions were longer and used different phrasing than they would ever use in a real text.
Changes to Solution Design
Based on these insights, we narrowed down our solution with the following considerations:
- Embedded Integration: The tool must be an embedded iMessage app or a background chatbot rather than a manual screenshot-based system. Users emphasized that it needs to be “easy access” to be used in real life.
- Concise and Authentic Messaging: Feedback needs to be shorter and more aligned with natural texting habits. Moving away from “AI-heavy” or overly “sassy” tones toward more direct, utility-focused guidance will likely increase trust.
- Transparency in Scoring: The solution should explicitly show what variables are contributing to a score. Participants wanted to know why their score was high or low and suggested that factors like lateness should be more heavily weighted.
- Addressing “Downstream” Factors: Future designs should focus on helping users reschedule more easily and avoid double-booking, as these were identified as the primary reasons for flaking rather than a simple lack of motivation.
- Selective Visibility: Given the mixed reaction to “shaming,” the design might offer options for private versus quasi-public scores within friend groups to leverage social pressure without causing undue anxiety.
System Path
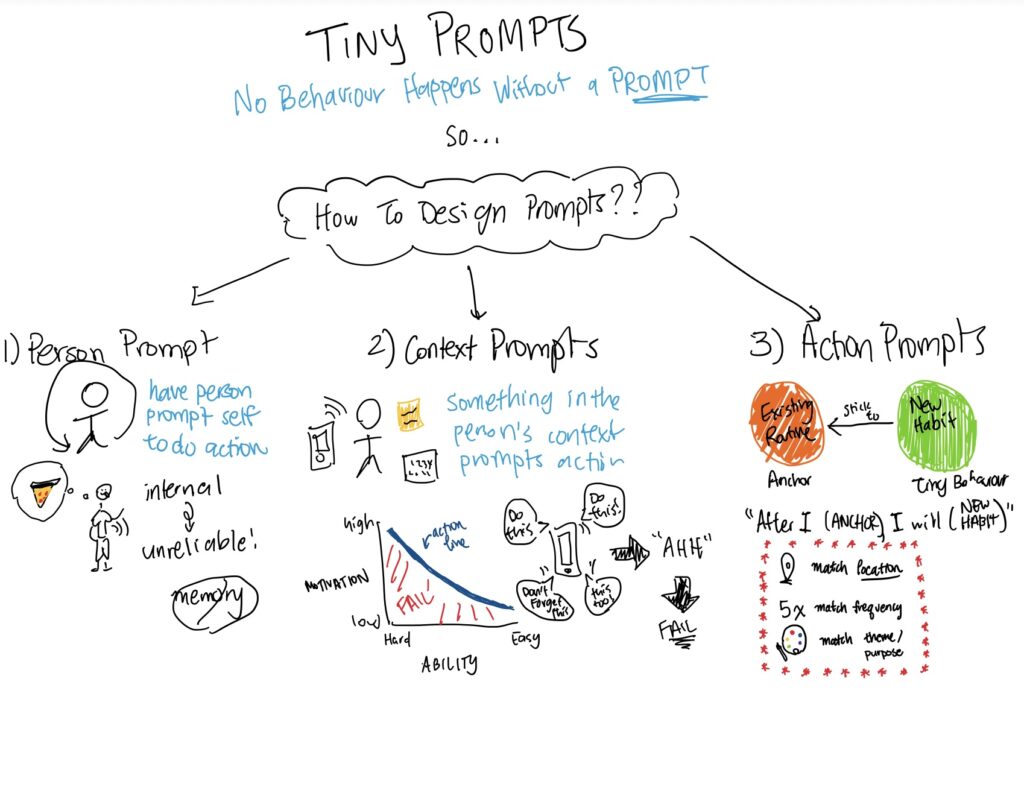
To create our system path, we identified the key actors: our chosen persona (a “chill guy”), our persona’s friends and co-planners, and our social bot. The path starts with our persona and their friends, as they have discussions over text. The bot automatically joins the path whenever social plans are discussed, facilitating seamless planning. In the planning phase, the bot dominates, managing scheduling and coordination details. Our persona and their friends reenter the path towards the end, turning planning into execution. The path also documents other potential flows with dashed lines, such as when rescheduling is necessary, or when some/all parties flake.
One key insight from the creation of this path was the roles of the different actors at different parts in the path. While the user (represented here by our persona) is heavily involved in the beginning and end of the process, the bot drives much of the intermediate action. This suggests that much of our features, supported by our social bot, will target this intermediary stage.
Story Map
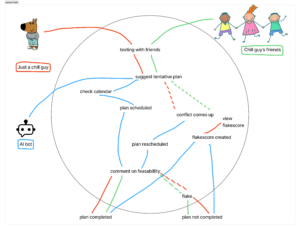
We identified the core goals, actions, and implementation details at each step in the user’s journey. We built the map from the top down, focusing on core needs and processes first and brainstorming dopamine-producing “nice-to-haves” later on. Building out the implementation section top down also gave us more awareness of the technical processes and backend pipelines that were necessary to make the user experience seamless.
Aside from onboarding, our story map included three core goals or outcomes: plan formation, plan execution, and post-event reflection. These three categories provided three core feature areas from which we created our MVPs. More details on the relationship between our story map and MVP features can be found in the following section.
MVP Features
We summarized our story map into the following features:
- Scheduling
- Smart scheduling suggestions
- Creating an event to be added to both parties calendars
- Check-ins
- Pre-event check-in asking both parties if they’re still available
- Post-event outcome check-in
- Accountability
- Flake score based on user scheduling patterns
Rationale: Our MVP features support the minimal cycle in our solution for enforcing accountability: planning, feedback, confirmation, and analysis of the outcome. We intentionally excluded gamification and analytics features behind calculating the flake Score to focus on our core features interrupting the flaking process. Our scheduling features correspond to the section of the story map dedicated to making a social plan, where our features automate the scheduling process to reduce friction-driven flaking. Our check-in features span the section of the story map between plan formation and execution, and address the core need for mindfulness, since mindfulness drives intentional commitment. Finally, our flake score feature for accountability corresponds to the end of the story map, where users develop an understanding of their social habits overtime.
Bubble Map

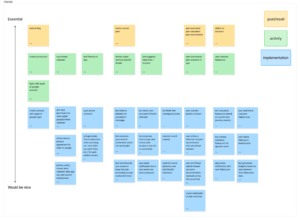
Our bubble map was constructed around the core insights from our interviews. The main reasons people flake became the three orange bubbles. We then added medium-sized bubbles representing different parts of our solution. Nitty gritty details, which are represented by the smallest circles, are mapped onto the relevant solution. Mapping our intervention visually here allowed us to see which features and solution components mapped onto which needs. The retrospective flake score, for example, which was the core of our intervention study, is driven by flaking behavior, and thus is related to each of the three reasons for flaking. That our bubbles were generally concentrated around the top left orange circle, which centered on plan vagueness, illustrates that most of our solution features address this need.
Assumption Map
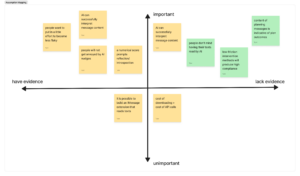
We documented several of the assumptions on which our solution hinges in this 2×2 map, categorized by importance for solution success and evidence (from interview insights and real-world knowledge). The most crucial assumptions, pictured in green, correspond directly to the assumption tests we decided to propose.
Our first key assumption is that users are willing to have their texts read by AI, with sufficient privacy protections. Because our solution takes the form of a messaging extension with access to message content, comfort with this level of AI access is a necessary precondition for using our solution. Although we have some priors about how much people are willing to share with AI, we did not cover this issue in our interview process, and we want to test the assumption specifically as it relates to text messaging and social planning.
Second, we assume that low-friction integration methods produce higher compliance. In our intervention study, we noticed that the friction caused by having to take manual screenshots and submit artifacts of social planning was high, causing some participants to forget and have to be reminded to submit. For our solution to work, we need to ensure that the friction caused by our data collection methods specifically caused this lack of compliance.
Lastly, one of the most important assumptions of our solution is that our social bot will be able to make accurate scheduling suggestions and generate representative flake scores. This hinges on the content of the planning messages. Messages must contain enough details for the bot to infer plan logistics and outcomes. We need to conduct further testing to observe how much planning is documented via text, versus retained from phone calls or in person communication.
Assumption Tests
Assumption 1
We believe that: People don’t mind having their texts read by AI so long as there are significant privacy constraints.
To verify this we will: Ask people to share texts with their preferred AI platform. See how they react. Ask them to explain their reaction.
And measure: Participant’s reactions (qualitatively).
We are right if: People openly share their texts, with minimal hesitation.
Assumption 2
We believe that: the manual friction of taking screenshots and submitting daily forms is the primary deterrent to consistent plan logging and effective real-time intervention
To verify this we will: conduct a comparative test between two groups: one continuing the manual “screenshot-to-bot” reporting method and another using a functional embedded iMessage app prototype that automatically detects potential plans within the chat interface
And measure: the total percentage of social plans successfully logged (verified against end-of-day interviews), the average time delay between a plan being made and its first bot interaction, and the rate of “forgotten” or “late” entries
We are right if: the group using the embedded prototype logs a significantly higher percentage of their total plans in real-time, avoids the “slacking” or “end-of-day” logging dumps seen in the manual study, and reports that easy access was the critical factor in their ability to maintain the habit
Assumption 3
We believe that: The content of planning-related messages is indicative of whether or not plans fall through
To verify this we will: Read text messages related to a social plan.
And measure: What details of the plan (location, time, punctuality, outcome, etc.) we can discern from the texts alone.
We are right if: We can successfully determine plan outcomes from the messages.
Tyler Abernethy, Vardhan Agrawal, Katherine Sullivan, Sunny Yu. Intervention Study Synthesis. March 3, 2026.