Assumption Map
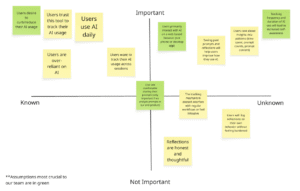
Mapping our assumptions revealed that the biggest risks in our AI intervention are behavioral rather than technical. While building a browser widget that tracks time and prompts is feasible, the success of the product depends on human psychology. Our solution assumes users want greater awareness of their AI habits, are comfortable being monitored, and believe that seeing their data will meaningfully change how they behave. If these assumptions fail, the product loses its core value and becomes just another analytics tool.
One of our most crucial assumptions is that users primarily interact with AI through web-based interfaces. Because our intervention exists as a browser widget, it can only capture meaningful behavior if AI usage happens in that environment. If users primarily rely on desktop apps, IDE integrations, or mobile apps, our tool would not reflect their real usage patterns. This is a foundational infrastructure assumption. If it is wrong, the product cannot function as intended.
Equally critical are our assumptions around trust and behavior change. We are asking users to allow tracking of their prompts and usage patterns, which can feel invasive if not positioned carefully. Without trust, users will not install or consistently use the tool. At the same time, we assume that awareness leads to reflection and more intentional AI use. If seeing usage data does not actually shift behavior, then the intervention fails to deliver meaningful impact. This mapping process made clear that our success depends less on tracking capability and more on perceived safety, seamless integration, and the ability to translate data into genuine self-awareness.
Assumption Tests
Test 1: Web-Based AI Usage
- We believe: Users primarily interact with AI tools through web-based browser interfaces.
- To verify, we will: Survey AI users (students or professionals) and ask them to estimate the percentage of their AI usage across environments: web browser, desktop app, IDE plugin, or mobile app. We can also ask them to check their browser history or screen time logs to improve accuracy.
- And measure: The percentage of total AI sessions occurring in web browsers.
- Criteria: We are right if
- At least 60–70% of AI interactions occur in web browsers.
- If less than 50% occur in browsers, our widget risks being irrelevant or incomplete.
Test 2: Comfort With Prompt Tracking
- We believe that: Users are comfortable installing a tool that tracks their AI usage, including prompt content.
- To verify, we will: Distribute a Google Form describing a research tool that tracks time spent using AI, number of prompts sent, and prompt content. Participants will be asked whether they would install a tool like this, what types of data they would feel comfortable sharing, and what privacy concerns or conditions would influence their decision.
- And measure: The percentage of respondents who say they would install the tool either without hesitation or with minor conditions (such as anonymization, local storage, or the ability to delete data).
- Criteria: We are right if,
Test 3: Tracking Leads to Self-Awareness
- We believe that: Seeing usage data about AI time, prompt frequency, and past prompts increases users’ self-awareness and leads to more intentional AI use.
- To verify, we will: Run a 5-day manual tracking experiment with 10 users. Participants will log how long they use AI and what they use it for. On Day 5, we will present them with a simple dashboard summary of their behavior and ask reflection questions about what surprised them and whether they would change their usage.
- And measure: The percentage of participants who report surprise, increased awareness, or intention to change their AI behavior.
- Criteria: We are right if,
- At least 50% report meaningful increased awareness or behavioral reconsideration.
- If most participants report no new insight or intention to adjust their behavior, our intervention’s core value is weak.