The Behavior I Chose to Change:
The behavior I chose to examine is accepting LLM-generated responses without engaging in critical thinking, particularly without verification, skepticism, or independent judgment. Importantly, this behavior is not about using LLMs frequently, nor about “overreliance” in a general sense. Instead, it concerns how I process LLM outputs once they are produced. In many cases, I noticed that I treated the response as good enough to act on simply because it sounded plausible, coherent, or context-aware, without pausing to question its accuracy or completeness.
This behavior appears most often when:
-
the task feels low-risk,
-
time pressure is present,
-
the response aligns with my expectations,
-
or the LLM maintains conversational continuity across turns.
I chose this behavior because it directly affects how knowledge is constructed, trusted, and acted upon, especially in research, technical, and professional contexts where plausibility is not equivalent to correctness.
Measurement Duration and Logging Method
I measured this behavior over two full working days (Friday and Monday). Rather than logging at fixed time intervals, I logged each instance where I encountered an LLM response and made a decision about whether to critically evaluate it.
For each instance, I recorded:
-
whether I accepted the response without critical thinking,
-
my perceived Motivation and Ability using the Fogg Behavior Model,
-
the situational prompt that led me to rely on the response,
-
contextual notes describing my reasoning,
-
and the broader task category (e.g., coding, research ideation, writing, website navigation).
This approach allowed me to focus not on surface-level usage, but on the cognitive step where evaluation could have happened, but often did not.
My Experience Logging This Behavior
Logging was initially uncomfortable because it revealed how automatic this behavior had become. In real time, accepting an LLM response without scrutiny often felt neutral or even rational. Only after writing down my motivation and ability did I notice how often acceptance was driven by convenience rather than confidence. I also realized that critical thinking was not absent because I lacked the skill, but because I withheld it when the perceived cost of being wrong felt low. The act of logging forced me to acknowledge that “low risk” is often an assumption rather than a fact. Over time, the logging process itself began to act as a soft intervention. I became more aware of moments when I stayed inside the LLM interaction loop, asking follow-up questions instead of independently verifying information.
Key Learnings From the Measurement
1. Acceptance Without Evaluation Is Strongly Context-Dependent
I was far more likely to accept LLM responses uncritically when:
-
motivation was low (fatigue, time pressure),
-
the response sounded confident and well-structured,
-
or the LLM referenced prior context, creating a sense of personalization.
In contrast, critical thinking emerged mainly after a trigger, such as detecting an obvious misinformation, a difference from my expectation, or missing/unclear references.
2. Conversational Continuity Replaces Evidence
One striking pattern was how context-aware responses increased trust, even without factual grounding. Because the LLM remembered earlier steps and tailored its language to my task, the response felt reliable. This reduced my impulse to question it. As a result, conversational coherence often substituted for verification.
3. Critical Thinking Is Deferred, Not Absent
I did not lack the ability to think critically; rather, I postponed it. In many cases, critical evaluation happened only after something went wrong or after dissatisfaction accumulated. This suggests that the behavior is governed more by timing and triggers than by skill or intention.
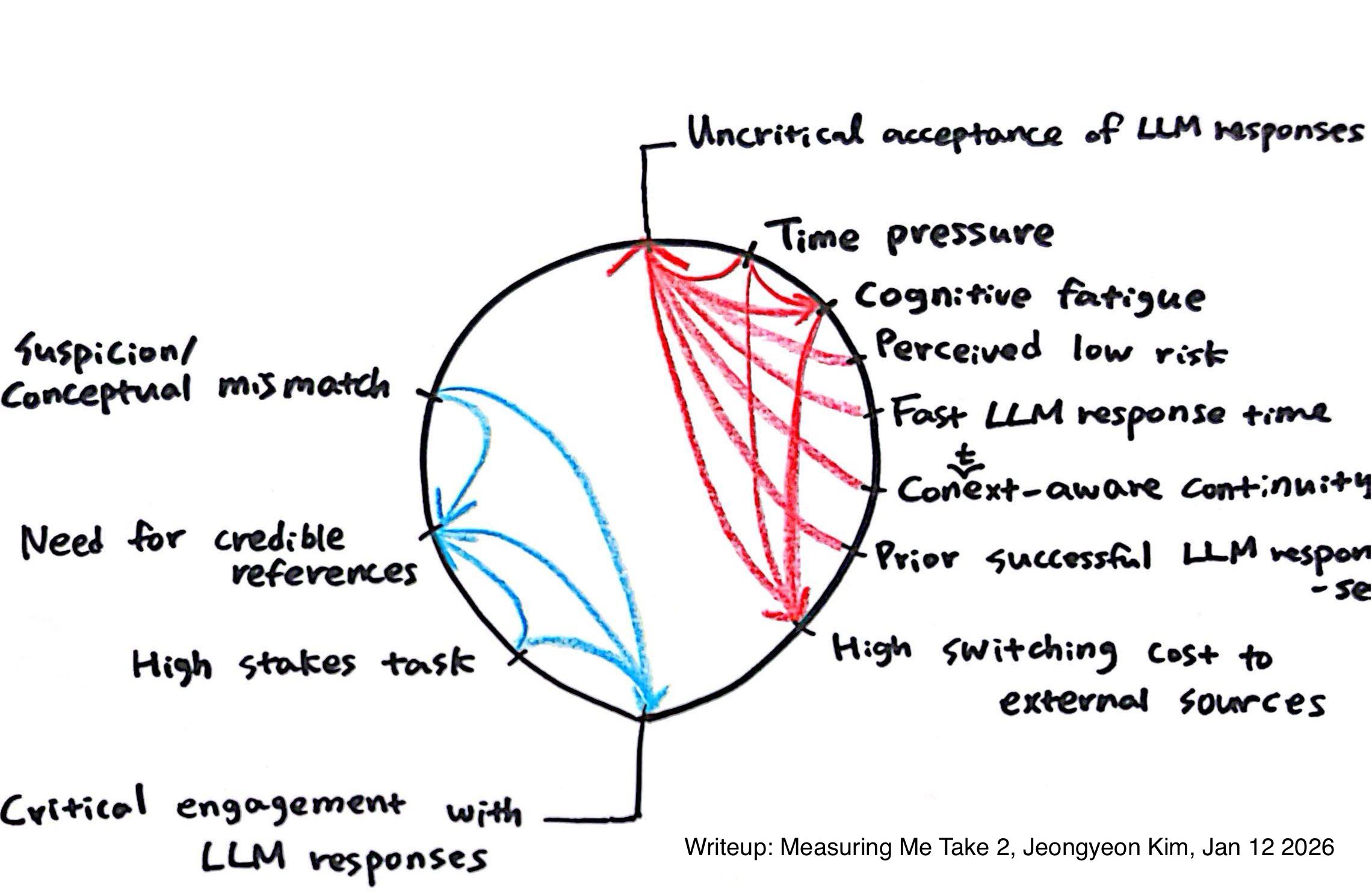
Model 1: Connection Circle
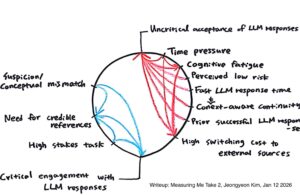
The Connection Circle models how accepting LLM responses without critical thinking is sustained by reinforcing loops:
Time pressure -> Cognitive fatigue -> High switching cost to external sources -> Uncritical acceptance of LLM responses
On the other hand, the reinforcing loop for critical thinking was below:
Suspicion/Conceptual mismatch -> Need for credible references -> Critical engagement with LLM responses
A key insight from this model is that critical thinking is not actively suppressed. Instead, it is systematically crowded out by forces that reward speed, continuity, and cognitive ease.
Model 2: Fogg Behavior Model
<Day 1>
| Time | Behavior happened? | Motivation | Ability | Prompt | Notes | Task |
| 9:00 | X | LOW | LOW | Encountered a command-line task that needed an immediate solution | Working in a terminal command-line environment. I generally trust the LLM’s suggested commands and try them directly without much skepticism. I only double-check via web search when errors occur or the command fails. | Coding |
| 9:06 | X | LOW | LOW | Faced a similar follow-up task after a previously successful command | The previous attempt felt reliable, and the next task was similar in nature, so I reused the LLM’s code without verification or critical evaluation. | |
| 9:10 | X | LOW | LOW | Noticed a suspicious part of the generated command while continuing the task | Some parts of the response felt suspicious, but instead of checking external references, I asked the LLM for clarification and elaboration. | |
| 9:16 | X | LOW | LOW | Needed to resolve uncertainty quickly without interrupting workflow | Asking again felt convenient, and even if the response was wrong, the risk seemed low. I stayed within the LLM loop, correcting it through additional prompting if needed. | |
| 9:25 | X | LOW | LOW | Received a context-aware response that appeared tailored to my ongoing task | Because the LLM remembered the task context and provided customized responses, the answers sounded more reliable and plausible. Searching for similarly customized information elsewhere felt more costly. | |
| 11:04 | X | LOW | HIGH | Reached an early brainstorming stage and wanted more idea variation | At the early stage of brainstorming, I had rough ideas but wanted to explore more creative and diverse possibilities. | Research Idea Brainstorming |
| 11:10 | X | LOW | HIGH | Asked a follow-up question to clarify and extend an initial idea | Through follow-up questions, the initially rough ideas gradually became more concrete and well-defined. | |
| 11:24 | X | LOW | HIGH | Identified promising directions and wanted to narrow them down | By repeatedly asking follow-up questions, I narrowed a broad idea space toward more promising directions. | |
| 11:59 | X | LOW | HIGH | Needed dataset-related information at the moment of planning | I needed dataset-related information, and even though this was more of a simple search task than synthesis, I asked the LLM directly instead of using a search engine. | Dataset Search |
| 12:05 | X | LOW | HIGH | Realized additional dataset details were required | I asked for more detailed dataset information (e.g., labels). | |
| 12:10 | O | HIGH | HIGH | Detected potentially incorrect or inconsistent information | I noticed suspicious or questionable information in the previous response. | |
| 12:12 | O | HIGH | HIGH | Failed to obtain clear source references from follow-up questions | Even after asking follow-up questions, I could not get clear references, so I eventually searched for and consulted the original source directly. | |
| 12:30 | X | LOW | HIGH | Decided to constrain the model using externally verified source text | I fed the original dataset information into the LLM and prompted it to generate responses strictly based on the provided sources. | |
| 12:35 | X | LOW | HIGH | Needed a quick comparison across multiple datasets | I prompted the LLM to compare multiple datasets. After a quick visual check, the results seemed roughly correct, so I used them as-is. | |
| 3:23 | X | LOW | MEDIUM | Needed to send a formal email to a professor | I used the LLM to refine an email to my professor, making the tone more polite and formal. | Email Writing |
| 3:25 | X | LOW | MEDIUM | Wanted to improve wording without changing factual content | Since this was purely a writing task, I comfortably used the LLM to revise and expand the email without fact-checking. | |
| 3:28 | X | LOW | MEDIUM | Finalized the email and prepared to send it | In the same context, I used the LLM’s response directly when sending the email. | |
| 3:40 | X | LOW | LOW | Needed to find an online tool quickly | Instead of using a search engine to find online tools, I started by asking the LLM. | Tool Search |
| 3:50 | X | LOW | LOW | Wanted more detailed information about suggested tools | I asked for more detailed information about each tool suggested in the previous response. | |
| 4:12 | O | HIGH | HIGH | Felt dissatisfied after checking suggested tools individually | After checking the suggested tools individually and finding them unsatisfactory, I switched from the LLM to a search engine. | |
| 5:30 | X | LOW | LOW | Encountered an error while using an insurance website | While using a health insurance website, I encountered an error and relied on the LLM for guidance on how to use the site overall. The response seemed reliable, including references to source material. | Website Navigation |
| 5:34 | X | LOW | LOW | Hit a login error that blocked progress | I encountered a login error on the website and resolved it using the LLM’s instructions. Since the solution worked without issues, my trust increased. |
<Day 2>
| Time | Behavior happened? | Motivation | Ability | Prompt | Notes | Task |
| 10:30 | X | LOW | HIGH | Faced a complex, under-structured research idea with many stakeholders | Research idea was still raw and fragmented. LLM was used to externalize thinking and reduce cognitive load in structuring the problem space. | Research Ideation |
| 10:40 | X | LOW | MEDIUM | Asked the LLM to generate multiple creative versions of research ideas | Used LLM as a divergence engine to explore alternative framings beyond my initial mental model. | |
| 10:47 | X | LOW | LOW | Needed help articulating tacit knowledge challenges in surgery | Tacit knowledge felt difficult to verbalize precisely. LLM was used to probe language and conceptual framing. | |
| 10:55 | X | LOW | MEDIUM | Attempted to connect datasets to research ideas | LLM helped surface dataset affordances and limitations, even though confidence in factual accuracy was moderate. | |
| 11:05 | X | LOW | MEDIUM | Wanted to recall limitations of the dataset without re-reading papers | Relied on LLM’s high-level recall instead of verifying details immediately, prioritizing uninterrupted workflow over accuracy. | |
| 11:15 | X | LOW | HIGH | Sought help transforming raw bullet points into a coherent system idea | LLM functioned as a synthesis partner, stitching disparate notes into a plausible pipeline narrative. | |
| 11:25 | X | LOW | HIGH | Needed to define belief dimensions for stakeholder mental models | LLM supported structured enumeration of abstract cognitive variables (goal belief, risk salience, role expectation). | |
| 11:35 | X | LOW | HIGH | Wanted examples of coordination failures to ground abstract ideas | Used LLM to simulate plausible OR scenarios instead of sourcing empirical cases immediately. | |
| 11:45 | X | LOW | MEDIUM | Attempted to articulate why these failures are hard to teach | LLM helped translate intuition (“hard to teach”) into academically acceptable problem framing. | |
| 11:55 | X | LOW | MEDIUM | Needed to draft a professional “User Needs and Challenges” section | Treated LLM as a first-pass academic writer to establish tone and structure. | |
| 12:05 | O | HIGH | HIGH | Noticed that bracketed phrase felt conceptually weak or generic | Detected mismatch between generated text and true research contribution; paused LLM reliance. | |
| 12:10 | O | HIGH | HIGH | Wanted to rewrite the problematic sentence based on stronger theory | Shifted from generation to critique mode; LLM output became object of evaluation, not authority. | |
| 12:15 | X | HIGH | HIGH | Asked for multiple rewritten versions grounded in credible references | Re-engaged LLM, but now with stricter constraints and clearer expectations. | |
| 12:25 | X | LOW | HIGH | Wanted suggestions for improvement room backed by literature | Used LLM as a literature-informed critic rather than a creative generator. | |
| 12:40 | X | MEDIUM | HIGH | Continued refining narrative coherence across paragraphs | At this stage, ability was high, but LLM still reduced micro-friction in wording and flow. | |
| 12:55 | O | HIGH | HIGH | Felt confident enough to judge text without further LLM input | Cognitive ownership of the idea increased. LLM no longer necessary for this subtask, like further writing and idea development. |
Mapping my behavior onto the Fogg Behavior Model revealed clear patterns:
-
Low Motivation + High Ability
→ I could evaluate the response, but choose not to, accepting it at face value. LLM is used as a cognitive shortcut (brainstorming, dataset lookup), often without rigorous verification. -
Low Motivation + Low Ability
→ Acceptance becomes almost automatic, especially in technical troubleshooting. LLM becomes the default action, especially for coding, troubleshooting, and search-like tasks. -
High Motivation + High Ability
→ Critical behavior (fact-checking, source verification) appears, but only after a trigger (suspicion, dissatisfaction).
This model helped me see that motivation—not ability—is the primary bottleneck for critical engagement.
Cognitive Offloading in Creative Tasks
- The LLM demonstrably lowers the cognitive effort required to externalize complex ideas. However, this reduction in effort also collapses meaningful distinctions between uncertainty, intuition, and argument. When vague intuitions are quickly translated into polished academic language, the resulting text can obscure the epistemic status of the underlying idea. e.g., LLM was used to articulate tacit knowledge or multi-stakeholder dynamics before I had fully specified my own internal model.
- Another concerning pattern is the tendency to remain within the LLM interaction loop when uncertainty arises, rather than turning to primary sources or empirical grounding. Even when I sense gaps (e.g., dataset limitations, missing surgical context), the first response is often to ask the LLM for clarification rather than to consult external materials.
What I Would Do Differently Next Time
If I were to repeat this experiment, I would change both how I measure and how I intervene:
-
Introduce a Mandatory Evaluation Step
I would explicitly log whether I asked at least one evaluative question (e.g., “What could be wrong with this?”) before acting on an LLM response. -
Distinguish Acceptance From Use
Next time, I would separate “reading the response” from “acting on it” to better capture where critical thinking drops out. -
Add a Trigger Awareness Column
Logging what triggered skepticism (or failed to) would help identify leverage points for behavior change. -
Design a Friction-Based Intervention
Rather than relying on willpower, I would introduce small structural friction—such as switching tools or briefly consulting primary sources—before accepting responses in high-impact contexts.